Database System course notes.
1. relation model
1.1. schema & instance
Def: dabase table(instance)
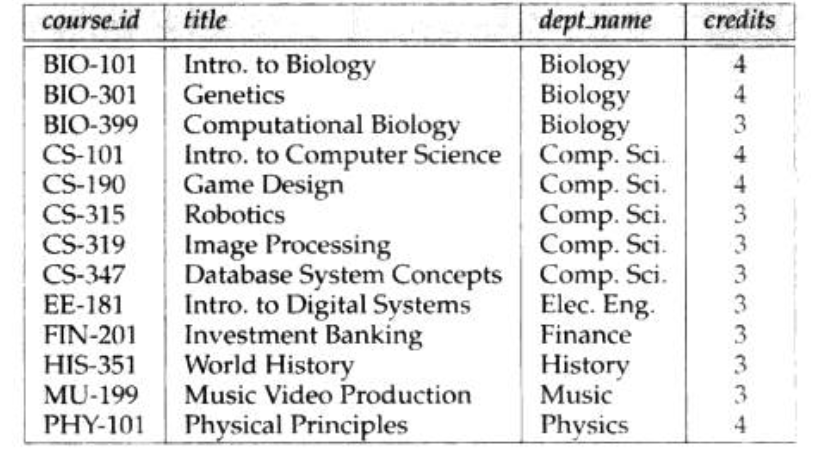
Def: relation instance

Def: domain is range of attribute
Def: database schema,就是设计模式,抽象的东西。
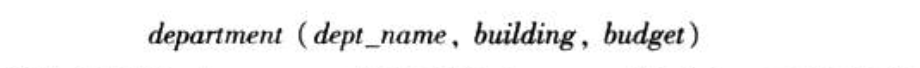
Def: superkey (is a set),一个超码是多个属性的集合,能够唯一标示一个元组

Def: candidate key (is a set),一个候选码是某一个超码的子集,且真子集不是超码,意思就是不能再减少属性的超码,毕竟超码可能有冗余。所有候选码是所有超码的子集

Def:primary key 是从候选码里选一个。

- Note: pk \(\in\) candidate \(\in\) super
Def: foreign key,x参照y是因为y在r2是主码。r1是y的参照关系,r2是y的被参照关系。

Def:参照完整性约束
r1 在 k 属性上的取值是r2 在 k 属性(属性名称可能不一样)上取值的子集。就是如果你包含别的模式的主码,你的取值不能超过该主码在自己模式的取值范围。
1.2. schema diagram
Def: schema diagram
2. SQL
2.1. basic structure
2.1.1. create
Def: create table
CREATE TABLE Persons ( PersonID int, LastName varchar(255), constraint_name FirstName varchar(255), constraint_name Address varchar(255), constraint_name City varchar(255) constraint_name );
Note: constraint
在 SQL 中,我们有如下约束:
- NOT NULL - 指示某列不能存储 NULL 值。
- UNIQUE - 保证某列的每行必须有唯一的值。
- PRIMARY KEY - NOT NULL 和 UNIQUE 的结合。确保某列(或两个列多个列的结合)有唯一标识,有助于更容易更快速地找到表中的一个特定的记录。
- FOREIGN KEY - 保证一个表中的数据匹配另一个表中的值的参照完整性。
- CHECK - 保证列中的值符合指定的条件。
- DEFAULT - 规定没有给列赋值时的默认值。
Def: create index
CREATE UNIQUE INDEX index_name ON table_name (column_name)
2.1.2. select
Def:
SELECT [DISTINCT/ALL] column_name AS alias_name,column_name
FROM table_name as...
[WHERE] column_name (一条比较一条)
OPERATOR SOME/ALL (嵌套子查询)
OPERATOR value
LIKE pattern
BETWEEN value1 AND value2/
)
[WHERE] column_name (一条比较一个集合)
IN (一条对比嵌套子查询)
UNIQUE (一条插入嵌套子查询)
EXISTS(一条插入嵌套子查询)
)
[AND/OR]
(当使用aggregate函数的时候才能用) [GROUP BY] column_name;
(当使用了group by,且想) [HAVING] SUM(access_log.count) > 200;
[ORDER BY] column_name,column_name ASC|DESC;
[LIMIT] 2;
[INTO] newtable [IN externaldb]
- 可以用with 做一个临时table
- 可以用from(from)操作,里面是一个小table
- 可以用集合函数来操作嵌套子循环
- Def:运行顺序:
- from... where...group by... having.... select ... order by... limit
2.1.3. insert
Def:
INSERT INTO table_name (column1,column2,column3,...) VALUES (value1,value2,value3,...);
2.1.4. update
Def:
UPDATE table_name SET column1=value1,column2=value2,... WHERE some_column=some_value [AND/OR]
2.1.5. delete
Def:
DELETE FROM table_name WHERE some_column=some_value [AND/OR]
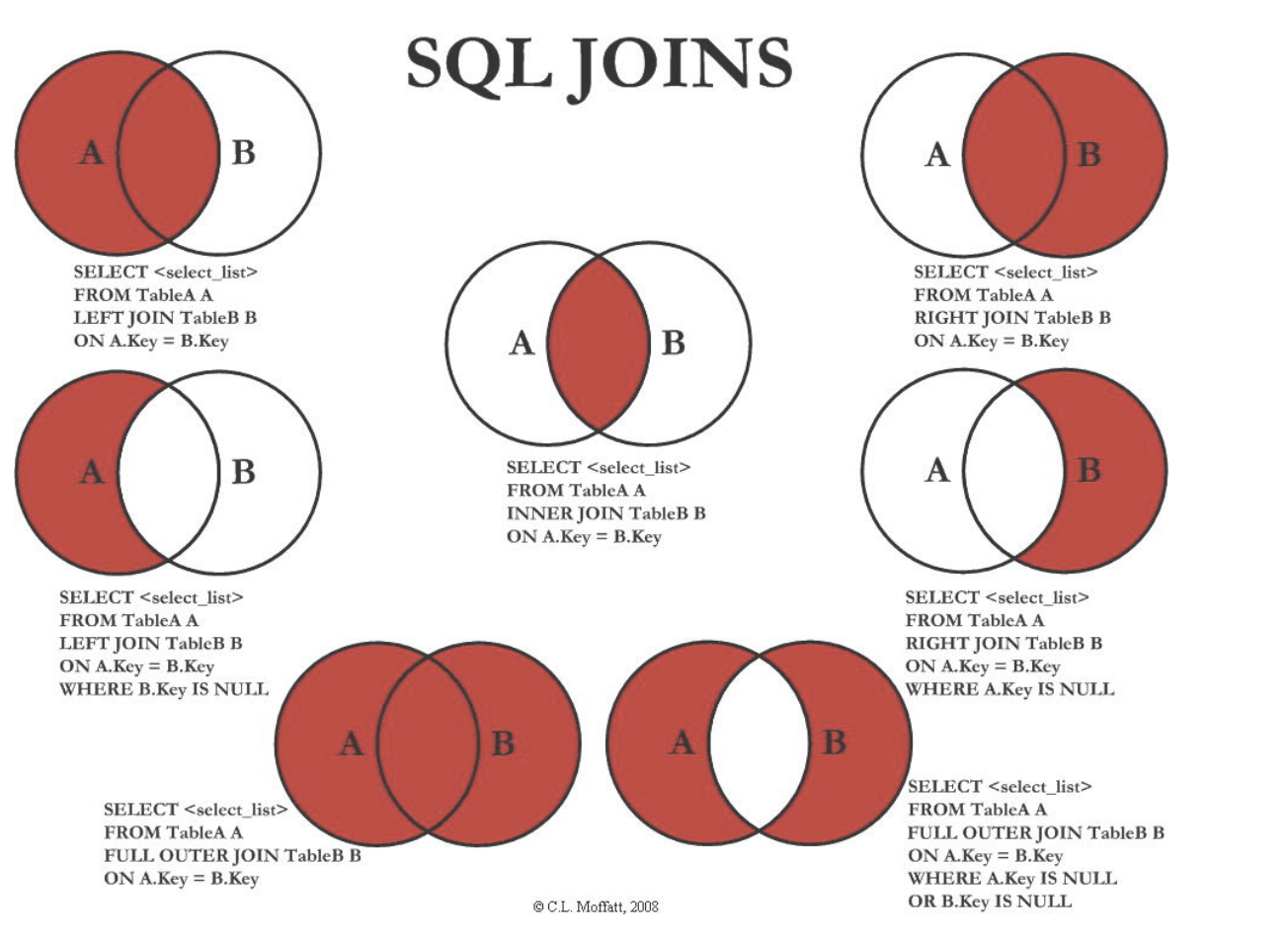
2.1.6. join
Def: join
[INNER] JOIN access_log ON/USING Websites.id=access_log.site_id;
Note: 简单来说,默认inner,有outer/left/right/natural等形式。natural比较特别,不需要on,而且默认也是inner连接。
2.1.7. alter
Def:
ALTER TABLE Persons
ADD DateOfBirth date(type)
DROP COLUMN DateOfBirth
2.1.8. functions
- Def: aggregate 函数计算从列中取得的值,返回一个单一的值。
- AVG() - 返回平均值
- COUNT() - 返回行数
- FIRST() - 返回第一个记录的值
- LAST() - 返回最后一个记录的值
- MAX() - 返回最大值
- MIN() - 返回最小值
- SUM() - 返回总和
- Def: SQL Scalar 函数基于输入值,返回一个单一的值。
- UCASE() - 将某个字段转换为大写
- LCASE() - 将某个字段转换为小写
- MID() - 从某个文本字段提取字符,MySql 中使用
- SubString(字段,1,end) - 从某个文本字段提取字符
- LEN() - 返回某个文本字段的长度
- ROUND() - 对某个数值字段进行指定小数位数的四舍五入
- NOW() - 返回当前的系统日期和时间
- FORMAT() - 格式化某个字段的显示方式
2.2. view
- Def:理解为一个临时表格。只有满足一些条件才能更新,
2.3. transaction
Def:

2.4. 授权图
- Def:
2.5. function
2.6. trigger
## algebra
2.7. 实现
- Def: https://www.cnblogs.com/Dhouse/p/6734837.html
3. database design
3.1. E-R
3.1.1. entity
Def: entity

Def:

3.1.2. relationship
Def: relationship


Def: 联系也有属性

Def: mapping cardinality

Note :
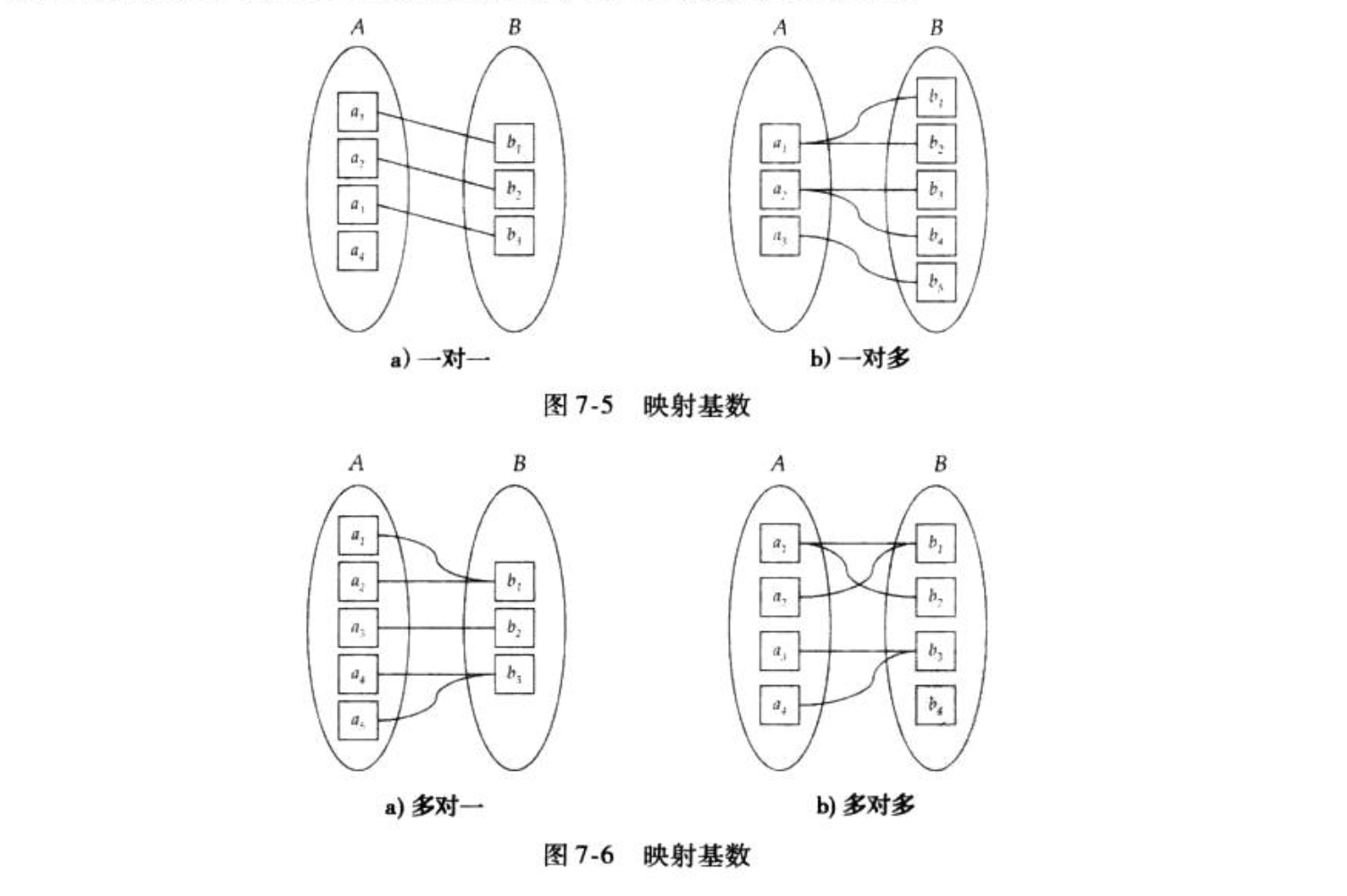
Def:联系也有约束(total/partial)
Def:联系集也有主码
- 多对多是主码并集
- 多对一是多的主码
- 一对一随意

Def:冗余属性,r1的主码在r2中出现且r1r2之间有联系的时候,可以把r2中的那一列去掉。
3.1.3. attributes
Def: 简单/复合

Note:
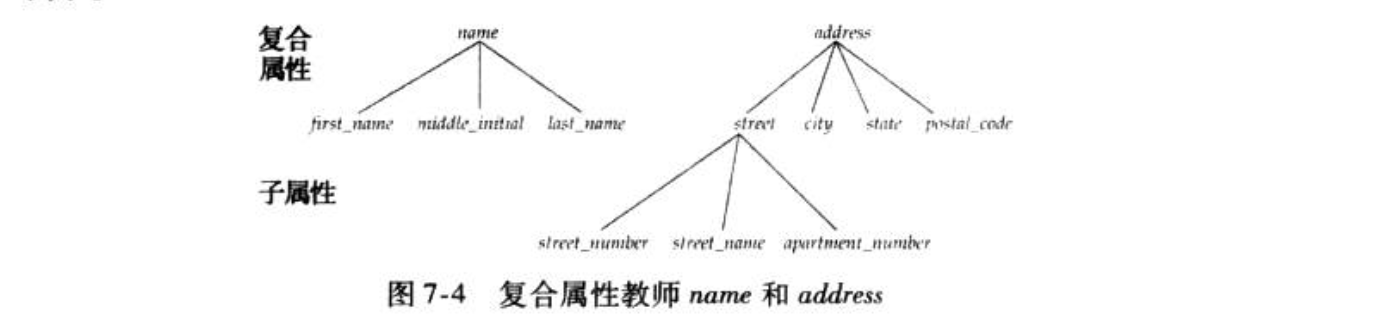
Def:感觉上是否是主码,主码就是单值,非主码可以有多值。


3.1.4. E-R map
Def:

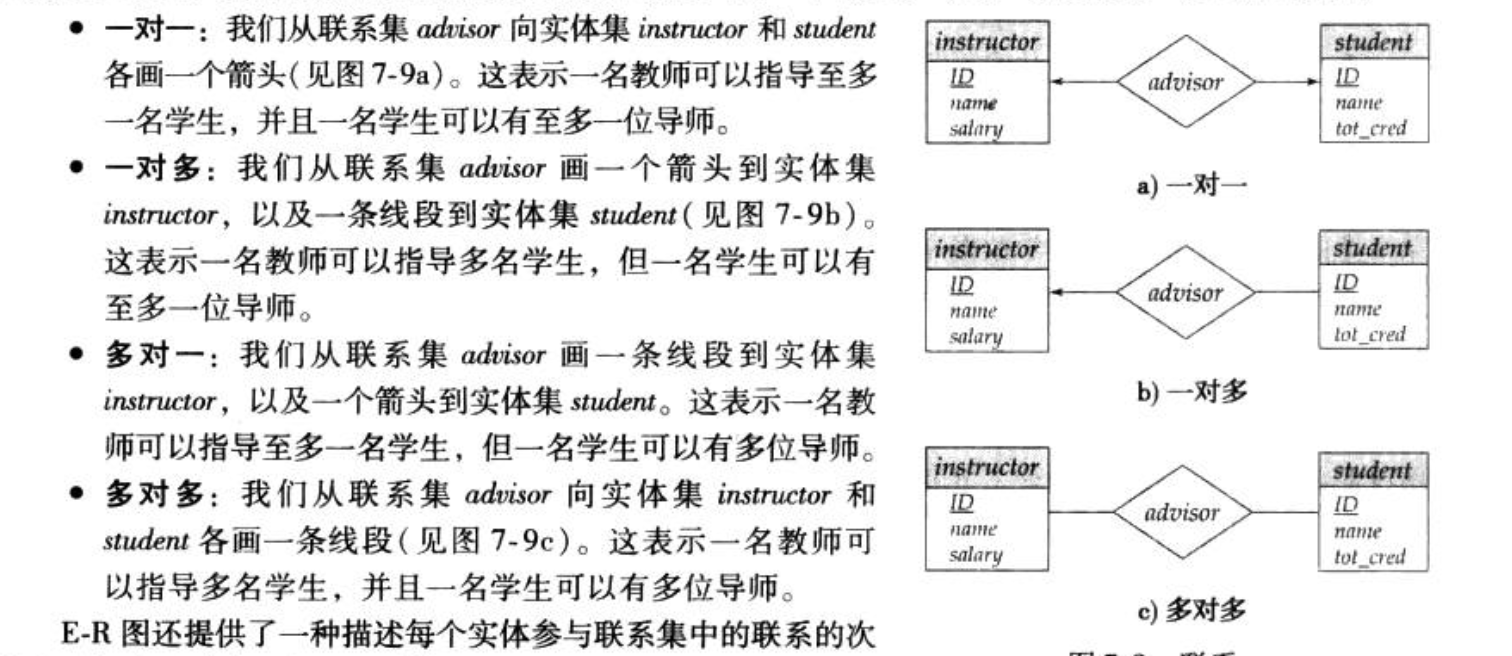

Def; 弱实体集就是没有主码,因为这个唯一主码体现了和别的集合的关系,如果去掉主码就雪崩;如果去掉联系集就不是好的ER图。所以这时候把主码去掉,然后把弱实体双线全部连接到主实体集,意思就是一个主实体对应多个弱实体。

Qua;

Qua:

Note:
3.1.5. relation model & E-R model
3.1.5.1. simple_a & strong_e
Def:

3.1.5.2. multi_a & string_a
Def:

Def: with multi_v , create another relationship

3.1.5.3. weak entity
Def:

3.1.5.4. relationship
Def:


Note:weak relationship is not necessary

Note: combination

3.2. decomposition
3.2.1. why?
Def : failed decomposition,分解后信息不对称了。所谓范式是针对依赖集和关系模式而定的,一个关系模式具有好的依赖集可能就会属于好的范式,分解之类的操作就会好。
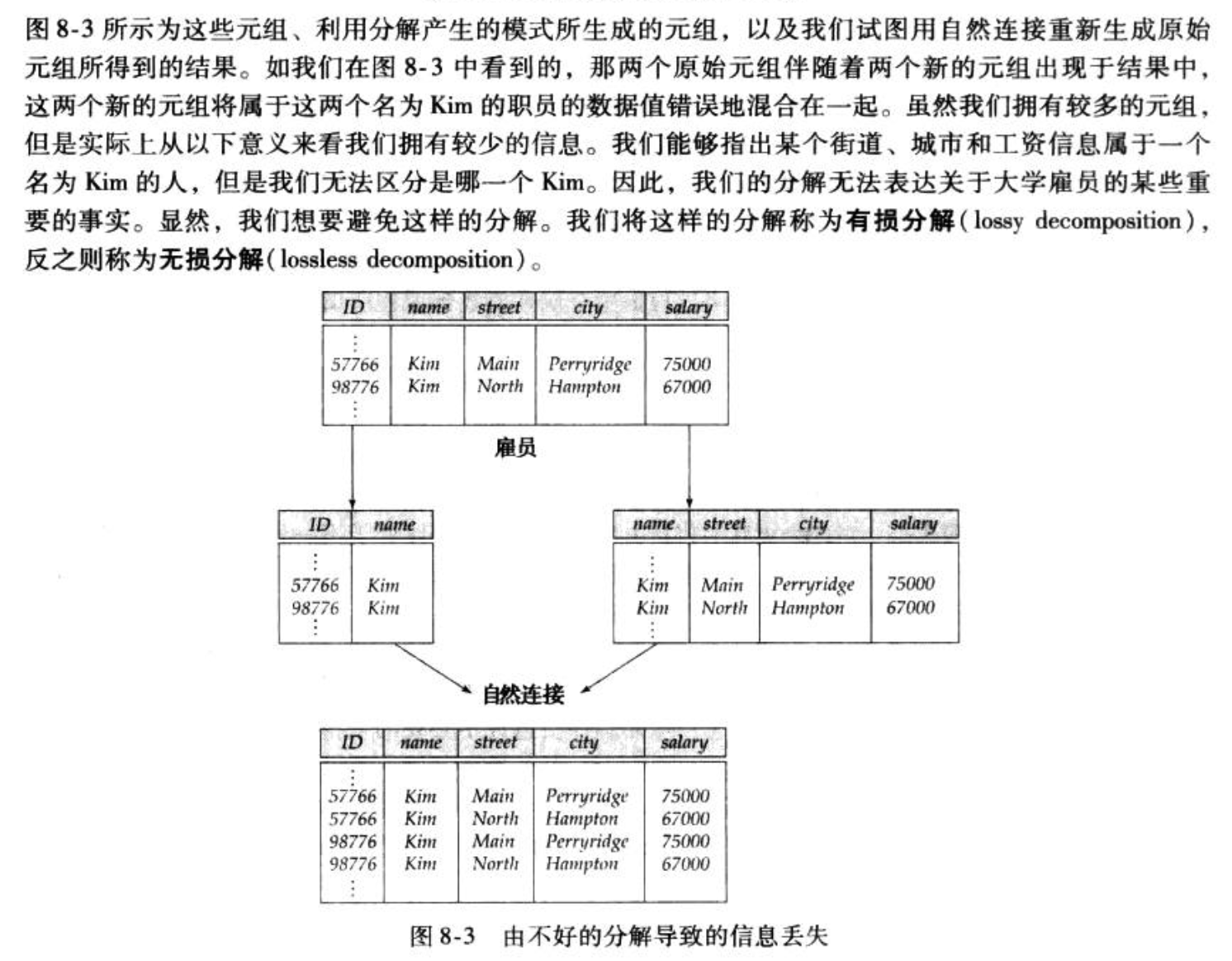
Def: 保持依赖:分解后原依赖集 = 后依赖集(后依赖集等于限定的并)

Qua:怎么判断?两种方法,一种是从整体出发,计算闭包,然后分解成限定,然后合并限定,然后计算闭包。另一个是检测每一条依赖,计算每一条限定下的result闭包,然后并起来。

Def:无损分解:分解后笛卡尔积不变。

Qua:怎么判断?如果R1和R2的交是R1或R2的超码。

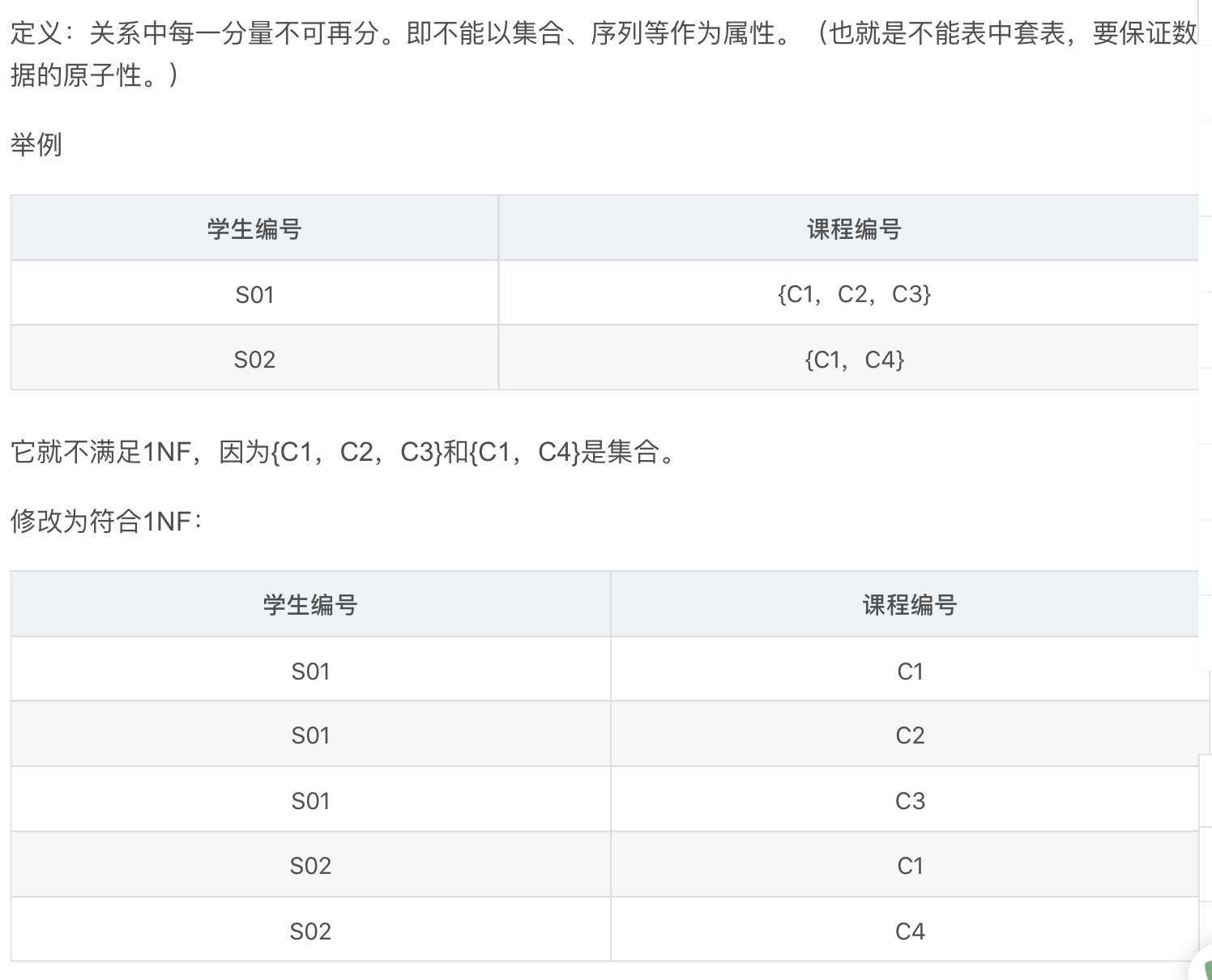
3.2.2. 1nf
Def: 1nf,意思就是所有属性都是原子的。

Note:

3.2.3. dependency
Def: candidate key
Qua: 怎么计算?先去掉只在右边出现的,加上只在左边出现的,加上都不出现的。其他的属性慢慢加,直到属性闭包等于全部。

Def: 依赖关系:a -> b 意思是a指挥b,意思就是如果两个元祖中a相等,那么b一定相等。

Note: 函数依赖定义的超码

Def:平凡依赖,a->b, b 属于a。
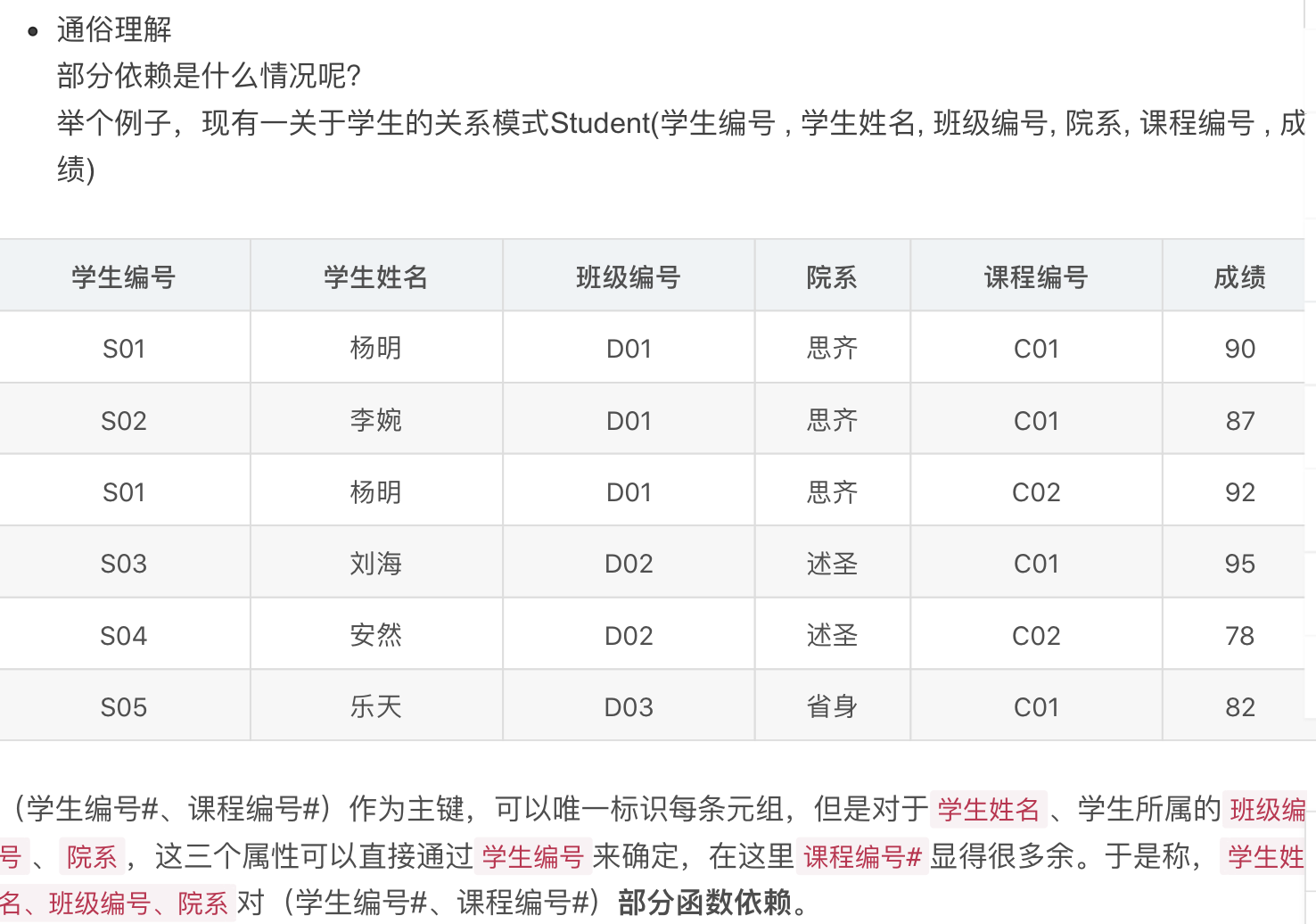
Def:部分依赖
Def:怎么推函数依赖,公理

Def: 依赖集合
Def: 依赖集合的闭包:所有可推出的函数依赖集合。

Def:计算某一个属性的闭包(左侧都是某一个属性的闭包,是整体闭包的子集),就是从属性开始,遍历每个函数依赖,如果函数依赖左侧被属性包含,就把右侧加入属性。

- Def:依赖集合的无关属性:去掉该属性不改变闭包
- Qua: 怎么计算?用闭包;F可以推出用除了该条依赖并上左边减掉后;用除了该条依赖并上右边减掉后 推出Fz
Def:依赖集合的最小覆盖er

Def: 依赖集合的正则覆盖,是一个和原依赖集相互推出的一个依赖集合,意思就是等价。而且包含一些性质(去掉了无关属性,左半部是唯一的)

Qua:怎么计算:先合并。遍历所有函数依赖,去掉对应的无关属性。

Qua: 正则覆盖不一定唯一。

3.2.4. 3nf
Def: BCNF放宽,函数依赖左侧可以是超码,也可以是多了一个条件,多了一个条件就是没有传递函数依赖。

Note; third rule = no transitive dependencies

Qua:怎么检测额?按定义
Qua: 3NF分解(保持3NF、保持依赖且无损)

3.2.5. BCNF
Def: 所有依赖左边都是超码。



Qua: 怎么检测?1)按定义计算属性闭包,判断是否超码


Qua: BCNF简单分解 (不一定保持依赖)


Qua:BCNF分解(满足BCNF和无损),在不属于BCNF的模式上,寻找一个依赖,然后把该模式分了;依次延续。

4. index
Def: mysql 中的索引
主键(聚集)索引:屋里顺序和搜索码排序一致;一个表就一个,主键默认索引所以也叫主键索引。
1
create clustered index clustered_index on table_name(colum_name)
聚集索引就是按照每张表的主键构造一颗B+?树,同时叶子节点中存放的即为整张表的记录数据。
非聚集索引:物理顺序不按搜索码排序。
- 全文索引:
- 唯一索引:
- 普通索引
区别:通过聚集索引可以查到需要查找的数据, 而通过非聚集索引可以查到记录对应的主键值 , 再使用主键的值通过聚集索引查找到需要的数据。二次查询问题也是从这来的。
1
select username, score from t1 where username = '小明'
假如score没有索引、username是非聚集索引,那么就先找到主键id,然后通过主键找score。如果select是username + id的话,就没有二次查询了。
4.1. 全文索引
Def:为了模糊搜索(match(content),like)
通过数值比较、范围过滤等就可以完成绝大多数我们需要的查询,但是,如果希望通过关键字的匹配来进行查询过滤,那么就需要基于相似度的查询,而不是原来的精确数值比较。全文索引就是为这种场景设计的。
4.2. 覆盖索引
- Def:包含了select/where涉及的列。
## 最左前缀
Def:最左前缀原则
而最左前缀原则指的是,如果查询的时候查询条件精确匹配索引的左边连续一列或几列(顺序无所谓),则此列就可以被用到。如下:
1
2
3
4
select * from user where name=xx and city=xx ; //可以命中索引
select * from user where name=xx ; // 可以命中索引
select * from user where city=xx ; // 无法命中索引在创建联合索引时,索引字段的顺序需要考虑字段值去重之后的个数,较多的放前面。ORDER BY子句也遵循此规则。
5. transaction
5.1. transaction
Def: 事务的性质
- 原子性,要么反应要么不反应,不能再分
- 一致性,保持数据库(应用系统从一个正确的状态到另一个正确的状态)也就是在给定的约束下,数据库语句总能得到正确的结果。
- 隔离性,事务之间觉察不到存在
- 持久性,永久的

Def: 事务的状态

Note:
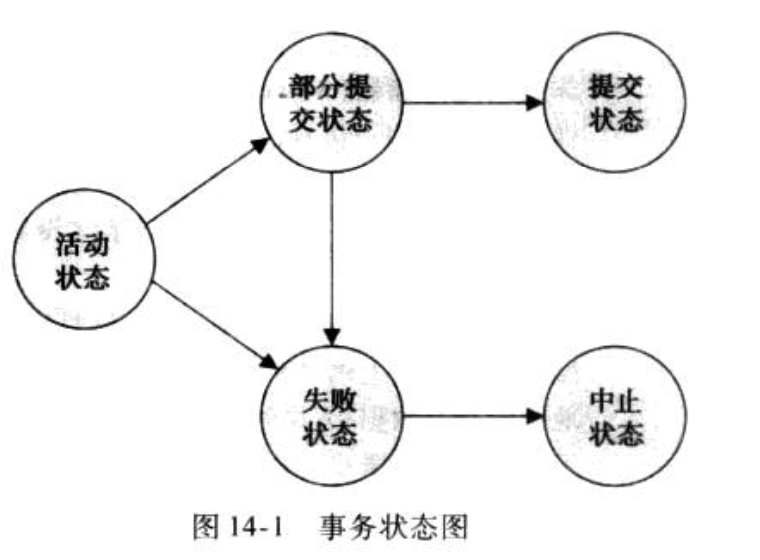
Def:sql隔离等级如下。数据库并发控制的目的是,让所有尽可能调度都和串行等价,因为串行一定是正确的解。


5.2. 隔离性
Def:为什么要并发(注意是并发不是并行)?
- 吞吐率(事务数/时间),CPU和IO可以并行执行,比如T1先来一个CPU,T2来一个IO然后就可以增加吞吐量。
- 减少等待时间(事务完成-提交),其实和上面类似的。
Def: 并发隔离级别:就是对调度的约束。
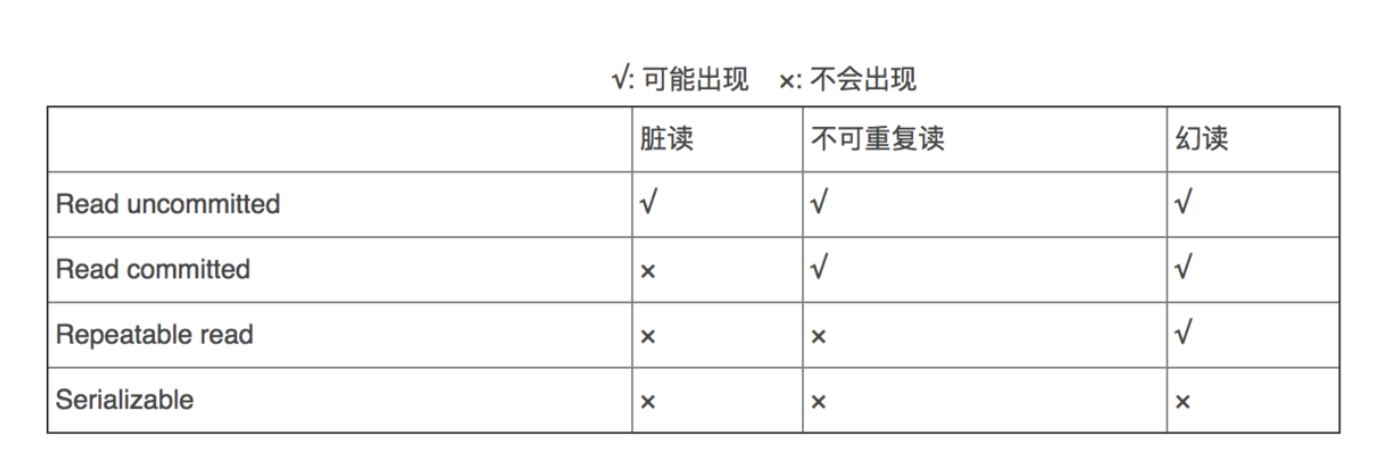
可串行化(针对所有):这个是最高级别的了,也就是调度等价于串行,但是约束也很大。
可重复读(针对脏读+不可重复):只允许读已提交数据,一个事务两次读一个数据期间其他事务不得更新。
已提交读(针对脏读):只允许读已提交数据。
未提交读:允许读未提交数据。
Def:不同隔离级别可能的问题
脏写:事务1写入了事务2写入但没提交的数据。
脏读:(事务1第二次读取时)读到了事务2未提交的数据。若事务2回滚,则事务1第二次读取时,读到了脏数据。
不可重复:(事务1第二次读取时)读到事务2已提交了数据。导致事务1前后两次读取的数据不一致。
幻读:(事务1第二次查询时)读到了事务2insert的数据。(不可重复针对值不一样,幻读针对条数不一样)
5.2.1. schedule
Def: 调度和串行:
- 调度:一个调度指的是很多个process的按照时间线来的操作。
串行指的是一个调度中,所有来自相同事务的聚在一起。

Def: 冲突等价和冲突指令:
- 冲突等价:就是等价
- 冲突指令:指的是一条包含write,一条不包含,这样两个不能交换。

Def:可串行化:和某一个串行调度等价
Qua: 怎么判断:
拓扑排序:画一个图,i->j有边当且仅当存在一条指令,i在前,j在后,然后i和j中间有一个write。如果有环是不行,无环可以。

5.2.2. 可恢复 schedule
Usage:为什么需要这个定义?
因为可恢复+无忌廉能够使得rollback操作容易完成,使得更好的满足隔离性和原籽性。
Def:可恢复:
如果i读取了j写过的数据,那么i比j提前提交(这是因为如果i还没交就挂了,我们需要rollback j,但是j已经交了就完蛋了)
Def:无及联:
如果i读取了j写过的数据,那么i在j的第一个读操作前提交。
5.2.3. lock实现
Def : 锁的种类。

Def : 锁的相容性

Def:怎么实现锁的管理?
通过lockmanager,一个锁表,类似hashtable
Def:希望的锁协议性质
- 可串行化
- 可恢复
- 无忌廉
- 无死锁
5.2.3.1. 2-phase
Def: 两阶段协议(保证serialization )
- 以第一个释放锁为节点,不能再获得新锁。
- 锁升级只能发生在节点以前
- 锁降级只能发生在节点以后

Def: 严格两阶段(serialization + no cascade ,)
- 加上所有X锁必须在提交后释放。

Def: 强两阶段(serialization + no cascade + no deadlock)
- 所有X,S锁必须在提交后释放。

Def:一个通用的加锁方法
- 读之前加S锁
- 写之前要么升级,要么加X锁
- commit后所有锁被释放

5.2.3.2. 乐观锁
Def:乐观锁(处理写写冲突)
总是假设最好的情况,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号机制和CAS算法实现。乐观锁适用于多读的应用类型,这样可以提高吞吐量,像数据库提供的类似于write_condition机制,其实都是提供的乐观锁。在Java中java.util.concurrent.atomic包下面的原子变量类就是使用了乐观锁的一种实现方式CAS实现的。
- 加一个版本号表示被修改的次数,当被修改时,修改前后版本号相等才更新否则回滚。
5.2.3.3. 行锁和表锁
Def: myISAM
- 用表级锁。
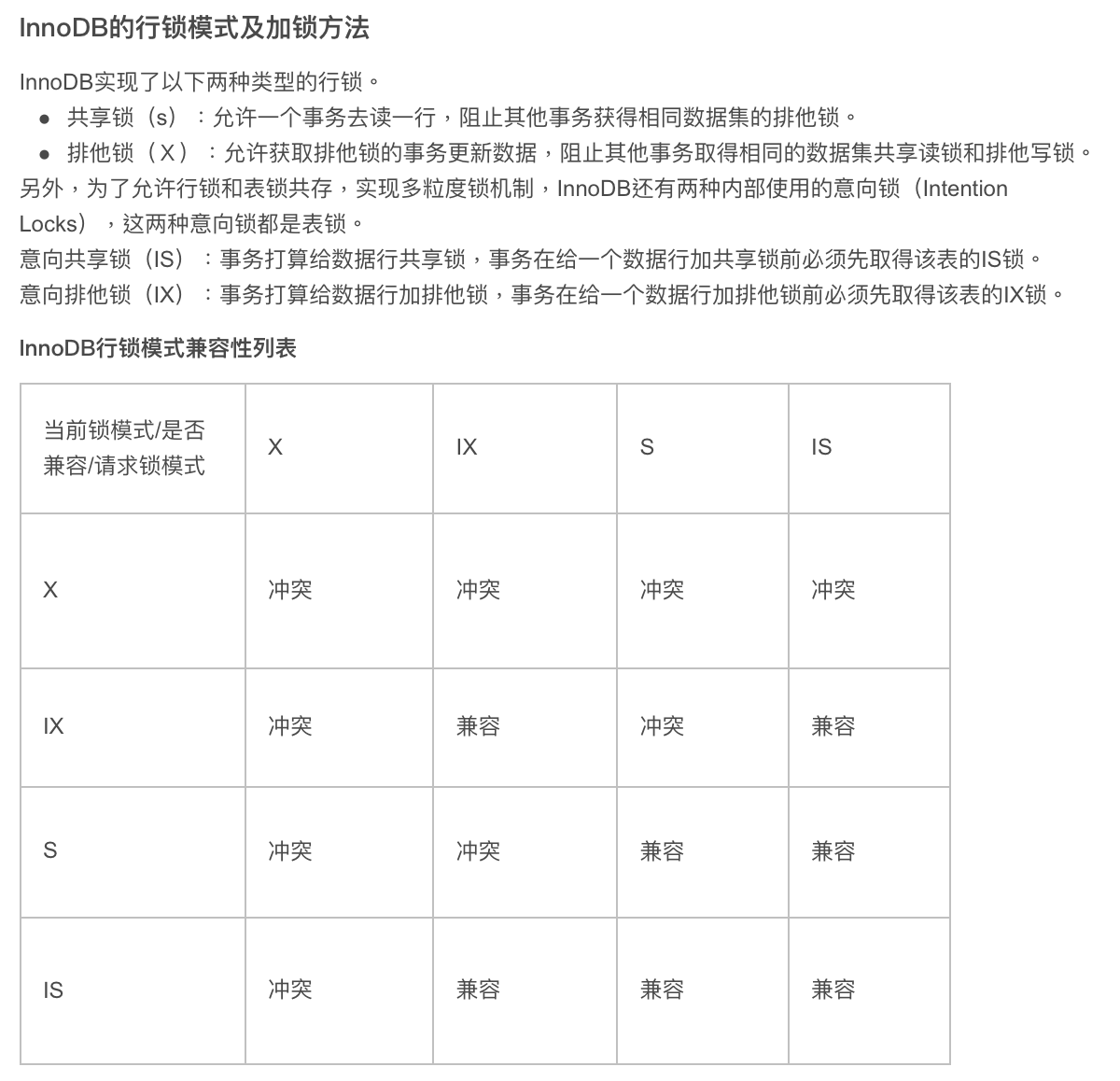
Def:innodb
支持事务(TRANSACTION)
采用了行级锁(innoDB行锁是通过索引上的索引项来实现的,这一点MySQL与Oracle不同,后者是通过在数据中对相应数据行加锁来实现的。InnoDB这种行锁实现特点意味者:只有通过索引条件检索数据,InnoDB才会使用行级锁,否则,InnoDB将使用表锁)
Def: 具体实现行锁:
X、S的兼容性不变,IS, IX之间互相兼容(为了简单性),且只有IS和S是兼容的表示可以多人读。
1
2IN SHARE MODE = 共享锁
FOR UPDATE = 拍他锁
Def:什么时候用表锁?
第一种情况是:事务需要更新大部分或全部数据,表又比较大,如果使用默认的行锁,不仅这个事务执行效率低,而且可能造成其他事务长时间锁等待和锁冲突,这种情况下可以考虑使用表锁来提高该事务的执行速度。
第二种情况是:事务涉及多个表,比较复杂,很可能引起死锁,造成大量事务回滚。这种情况也可以考虑一次性锁定事务涉及的表,从而避免死锁、减少数据库因事务回滚带来的开销。
5.2.3.4. 间隙锁
Def: 间隙锁
当我们用范围条件而不是相等条件检索数据,并请求共享或排他锁时,InnoDB会给符合条件的已有数据的索引项加锁;对于键值在条件范围内但并不存在的记录,叫做“间隙(GAP)”,InnoDB也会对这个“间隙”加锁,这种锁机制就是所谓的间隙锁(Next-Key锁)
Example:
举例来说,假如emp表中只有101条记录,其empid的值分别是1,2,...,100,101,下面的SQL:
1
SELECT * FROM emp WHERE empid > 100 FOR UPDATE
是一个范围条件的检索,InnoDB不仅会对符合条件的empid值为101的记录加锁,也会对empid大于101(这些记录并不存在)的“间隙”加锁。
Note: 为什么?
- 防止幻读,以满足相关隔离级别的要求,对于上面的例子,要是不使用间隙锁,如果其他事务插入了empid大于100的任何记录,那么本事务如果再次执行上述语句,就会发生幻读
- 为了满足其恢复和复制的需要。有关其恢复和复制对机制的影响,以及不同隔离级别下InnoDB使用间隙锁的情况。
5.2.4. graph 实现
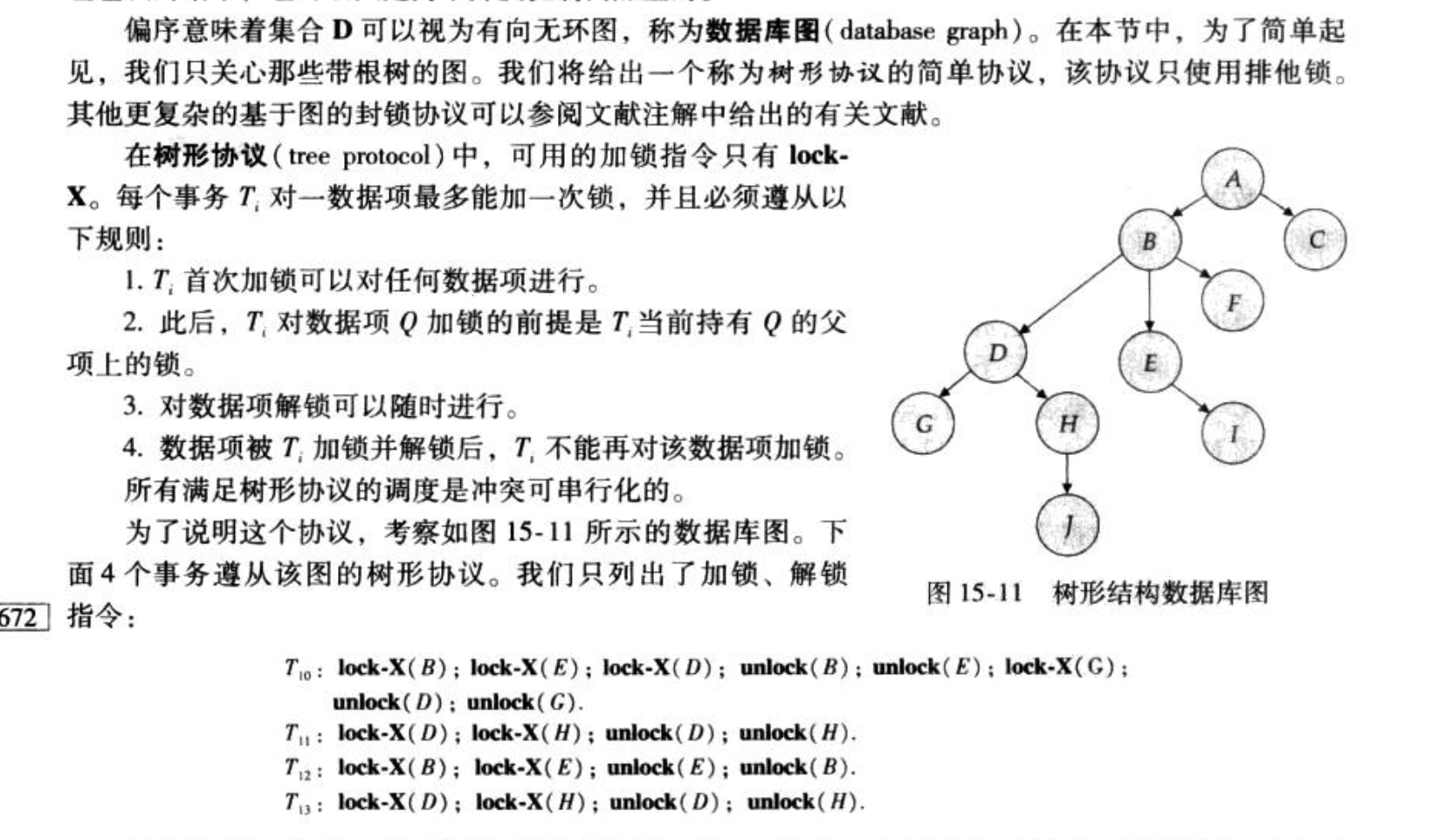
Def: 图协议:serialization + no deadlock
- 首先设计一个图,然后保证 一个T
- 对子节点加锁必须有父节点锁
- 加锁解锁后不能再加锁。
commit前不允许释放X锁(附加这一条可以保证可恢复性+无忌廉)

5.2.5. deadlock
5.2.5.1. prevention
Def: 加次序(破坏循环等待)

Def: 加抢占(破坏抢占)

Def:加超时(破坏占有并等待)

5.2.5.2. detection
Def: 等待图xu

5.2.5.3. recover
Def:
- 选择牺牲者并回滚,注意不要饿死(取消边)

5.2.6. timestamp实现
Def: 时间戳实现(serialization + no deadlock)
首先设置时间戳,事务时间戳等于第一条语句时间。

读的话,对比写时间戳
- 如果小的话,回滚;(意味着已经被晚来的别人写了,再读就不是串行)
否则执行。
写的话,对比读和写时间戳
- 如果小于读或者写时间戳都会滚;(意味着已经被晚来的别人读/写了,再写不是串行)
- 否则执行。



- Def:thomos 写规则(上述的改进)
- 写的话
- 如果小于写时间戳,则wirte忽略而不是拒绝。
- 写的话
5.2.7. mvcc 实现
Def: mvts 同样也是保证隔离性的机(serialization)
- 每个数据项有一个版本序列<Q1...Qn>,每个版本Q = <值,创建时间戳W,读取最大时间戳R>
- 每个事务通过write(Q) 创造一个新版本Qi,WR初始化为T,R会随着读取更新。
- 如果是读的话
- 返回Qmax,更新R。
- 如果是写
- 如果小于R,回滚
- 如果等于R,覆盖Q的值
- 如果大于R,创建新Q连到后面
- 如果是删除
- 小于R/W回滚,否则直接标记为删除即可。
- 如果某数据的两个版本W都小于最大事务时间戳,那么两个版本中旧版本可以删除。
- Note
- 好的特性,读不用等待!
- 坏的特性,读会两次磁盘访问;冲突必须回滚。
- Def:mvcc针对读写冲突的协议,保证read-committed
- 没有版本序列,而是加入“删除列”
- Q = <值,W,D> D表示删除的id,这个删除并不只是指那些delete操作,也包括了update,update实质是新插入一行,并且标记原有行为删除,这样才能让某一些事务只能读到以前的值
- update的事务提交执行以后,
- 新增一行,然后附上自己的事务id
- 再标记之前的那行数据的删除id。
- read的事务执行时
- 更新id小于等于当前id/删除id大于当前id, 读。只能读取“更新id小于等于当前id”可以保证repeatable read特性
- 否则回滚
- Note:保证read-committed,因为只有commit之后才写?
5.2.8. 快照实现
5.3. 隔离性:recover
5.3.1. 应该产生什么样的调度
- Def:可恢复,如果i读取了j写过的数据,那么i比j提前提交(这是因为如果i还没交就挂了,我们需要rollback j,但是j已经交了就完蛋了)
- Def:无及联,如果i读取了j写过的数据,那么i在j的第一个读操作前提交。
5.3.2. storage
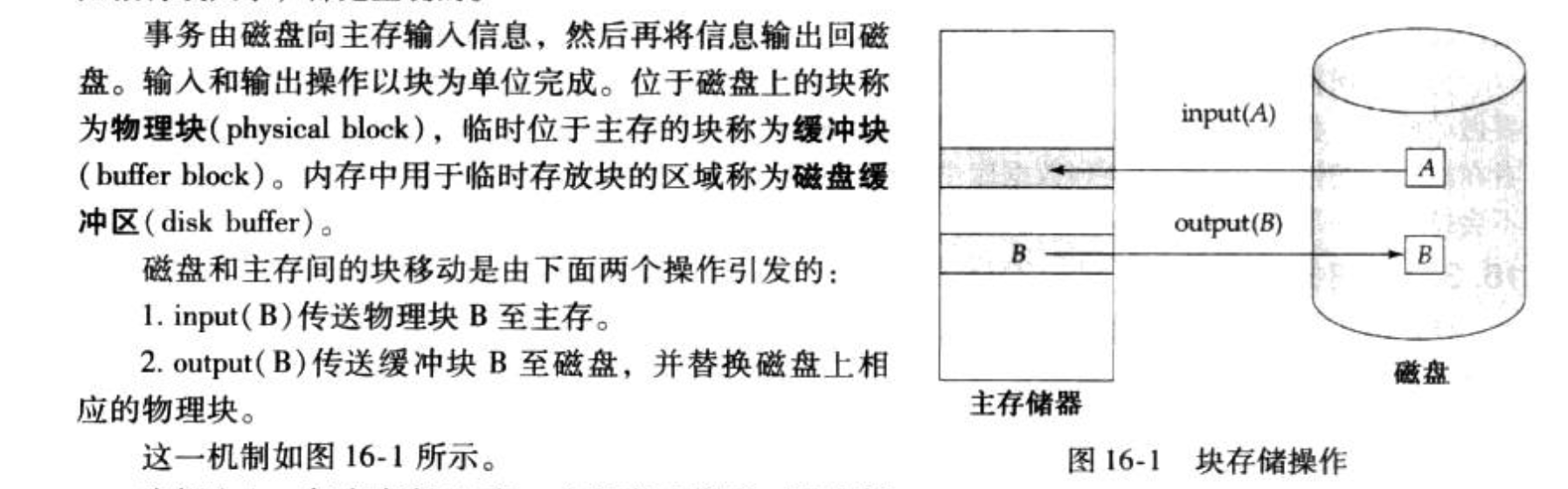
Def:内存—>disk

Def: 事务commit过程

5.3.3. log
Def: log 描述的是<事务,数据,写前,写后>

Def: 还有一些开始结束的其他特殊log

5.3.4. 恢复算法
Def:redo重做:
Def:undo回滚:从后往前,恢复旧值,写一个log表示已经undo,直到start写一个abort。

Def:恢复算法:没有commit/abort就撤销,有就重做。

具体来说,先从后到前扫重做一遍,然后找到没有commit/abort的操作,这是redo阶段。
在undo阶段一旦找到undolist中的东西就undo,遇到start就去掉,直到所有都undo完。
5.3.5. 检查点算法
- Usage:恢复算法需要搜索一边太麻烦
- Def:检查点干什么:
- 把所有log输出到disk
- 把所有修改的块输出到disk
- 写一个<checkpoint T1~Tn>表示检查时正在活跃的事务。
- Def:检查点算法:找到最后一条检查点,然后对检查点中涉及到的和之后才开始的事务进行恢复算法。
6. interview
6.1. 主从分离
Def:graph
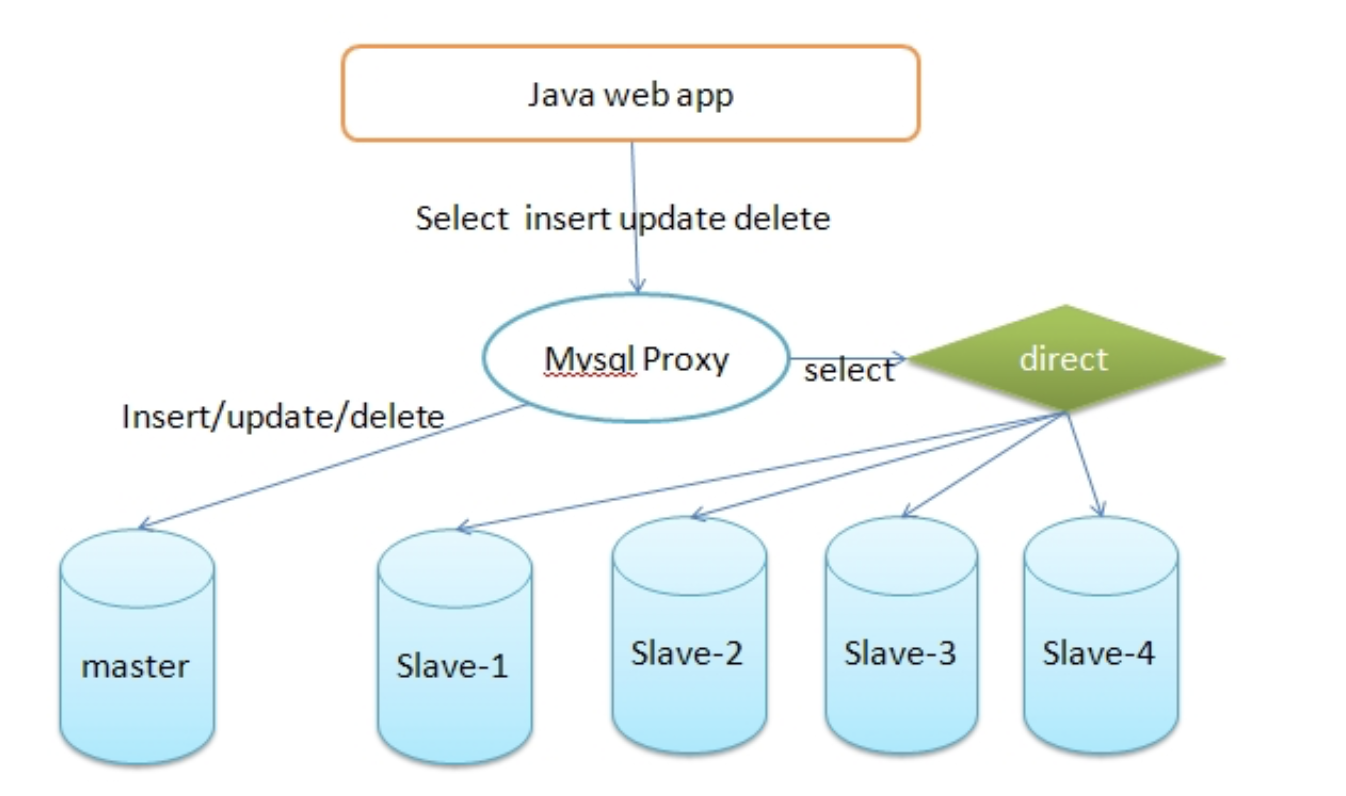
https://blog.csdn.net/itcats_cn/article/details/82155651
Def: 主从复制:是一种数据备份的方案。
简单来说,是使用两个或两个以上相同的数据库,将一个数据库当做主数据库,而另一个数据库当做从数据库。在主数据库中进行相应操作时,从数据库记录下所有主数据库的操作,使其二者一模一样。
Note: 具体怎么做?
1) 在每个事务更新数据完成之前,master在二进制日志记录这些改变。写入二进制日志完成后,master通知存储引擎提交事务。
2) Slave将master的binary log复制到其中继日志。首先slave开始一个工作线程(I/O),I/O线程在master上打开一个普通的连接,然后开始binlog dump process。binlog dump process从master的二进制日志中读取事件,如果已经跟上master,它会睡眠并等待master产生新的事件,I/O线程将这些事件写入中继日志。
3) Sql slave thread(sql从线程)处理该过程的最后一步,sql线程从中继日志读取事件,并重放其中的事件而更新slave数据,使其与master中的数据一致,只要该线程与I/O线程保持一致,中继日志通常会位于os缓存中,所以中继日志的开销很小。
Def:读写分离:是一种让数据库更稳定的的使用数据库的方法。
是在有从数据库的情况下使用,当主数据库进行对数据的增删改也就是写操作时,将查询的任务交给从数据库。
- Note: 什么意思?简而言之就是把读操作分摊到各个从数据库上。写的时候显然所有都不能读,这个操作时间无法分摊,但是读操作是可以分摊的。
6.2. delete truncate drop
https://blog.csdn.net/GRAY_KEY/article/details/86742248
- Note: 区别
- 删除的内容
- 是否可以回滚:delete可以,其他不行
- 是否触发触发器,维持约束性:delete可以,其他不行。
6.3. explain、慢查询日志、show profile等)
Def: mysqldumpslow慢日志
从慢查询日志中,我们可以看到每一条查询时间高于1s钟的sql语句,并可以看到执行的时间是多少
Def:Explain+SQL语句
使用EXPLAIN关键字可以模拟优化器执行SQL查询语句,从而知道MySQL是 如何处理你的SQL语句的。分析你的查询语句或是表结构的性能瓶颈。
Def:show profile
Show Profile是MySQL提供可以用来分析当前会话中语句执行的资源消耗情况,可以用于SQL的调优测量 默认关闭,并保存最近15次的运行结果
Def:count
加索引
Def;子查询的优化
变成join

